
One piece of data I wanted to have for my statistical analysis was the quality of college a player attended. I chose to measure college quality by the number of weeks a team was in the Associated Press (AP) Top 25 college basketball rankings. Note, that I only used regular season rankings not pre- or post-season rankings, which are not available for all years. Historic rankings dating back to the 2002-2003 season are available on the ESPN website. However, when scraping ESPN’s webpage I found the data was semi-structured.
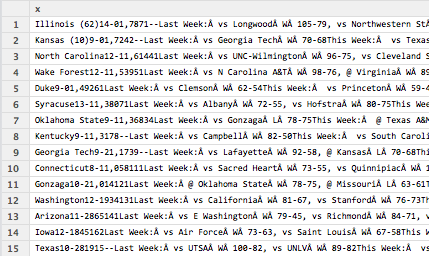
The code to read in the college name must be robust enough to ignore all the possible characters following the college name, but flexible enough to detect “exotic” college names like “Texas A&M” and “St. John’s.” The code first reads in each week’s rankings and strips out the college name. It then binds the weeks together. If the season has less than 18 weeks NAs are introduced to ensure every season is the same length and can be bound together. The college quality is then calculated for each season. Finally, the weekly rankings for every season are bound together into a single table and saved as is the college quality for every season. The code is shown below.
library(XML) library(data.table) # Initialize variables seasons <- seq(2013,2003,by=-1) allSeasonRankings <- NULL allSeasonTable <- NULL missedPages <- matrix(ncol=2,nrow=1) colnames(missedPages) <- c("Season","Week") k <- 1 # Web scrape # Iterate over each week in each season for(j in 1:length(seasons)) { numWeeks <- 0 seasonRanking <- NULL week <- NULL for (i in 2:19) { result <- try(week <- readHTMLTable(paste0( 'http://espn.go.com/mens-college-basketball/rankings/_/poll/1/year/', seasons[j], '/week/', i ,'/seasontype/2'),skip.rows=c(1,2))[[1]][,2]) if(class(result) == "try-error") { missedPages[k,] <- c(j,i); k <- k + 1; next; } print(paste0('http://espn.go.com/mens-college-basketball/rankings/_/poll/1/year/', seasons[j], '/week/', i ,'/seasontype/2')) numWeeks <- numWeeks + 1 week <- as.data.frame(array(BegString(week))) seasonRanking <- cbind(seasonRanking,week[[1]]) colnames(seasonRanking)[numWeeks] <- paste("Week",numWeeks) } # Ensure that all seasons have 18 weeks # (the maximum number of weeks in a season since 2003) # so that all seasons have the same length and can easily be bound together while(numWeeks < 18) { numWeeks <- numWeeks + 1 extra <- rep(NA,25) seasonRanking <- cbind(seasonRanking,extra) colnames(seasonRanking)[numWeeks] <- paste("Week",numWeeks) } # Bind seasons together allSeasonRankings <- rbind(allSeasonRankings, seasonRanking) # Calculate the percentage of weeks each school was in the AP Top 25 seasonTable <- as.data.frame(table(unlist(seasonRanking))) percentages <- round((seasonTable[2]/numWeeks)*100,2) # Change column name to "Top 25 %" immediately. Otherwise percentages will # inherit the name "Freq" from the table function and not allow use of setnames() # since 2 columns have the same name colnames(percentages)[1] <- "Top 25 %" seasonTable <- cbind(seasonTable, percentages) seasonTable <- cbind(seasonTable, rep(seasons[j],length(seasonTable[1]))) allSeasonTable <- rbind(allSeasonTable,seasonTable) } # Clean up names setnames(allSeasonTable,c("Var1", "rep(seasons[j], length(seasonTable[1]))"), c("Team", "Season")) # Add column with season rankingYear <- rep(seasons, each=25) # Combine data and cleanup names allSeasonRankings <- cbind(rankingYear,allSeasonRankings) allSeasonRankings <- as.data.frame(allSeasonRankings) setnames(allSeasonRankings,"rankingYear", "Season") # Save files write.csv(allSeasonRankings,file="~/.../College Quality/Season Rankings.csv") write.csv(allSeasonTable,file="~/.../College Quality/Percent Time in Top 25.csv")
The above code uses two custom functions to strip out the college name. One, strips out the college name and the second removes the trailing whitespace that sometimes occurs. There are a lot of different ways to do this. The most efficient is probably to use the functionality of the stringr package (such as string_extract()), but I wrote these functions when I was less aware of all of stringr’s functionality.
# Returns first string containing only letters, spaces, and the ' and & symbols BegString <- function(x) { exp <- regexpr("^[a-zA-Z| |.|'|&]+",x) stringList <- substr(x,1,attr(exp,"match.length")) stringList <- removeTrailSpace(stringList) return(stringList) }
# Removes trailing whitespace of a string removeTrailSpace <- function(stringList) { whiteSpaceIndex <- regexpr(" +$",stringList) whiteSpaceSize <- attr(whiteSpaceIndex,"match.length") for(k in 1:length(stringList)) { if(whiteSpaceSize[k] > 0) { stringList[k] <- substr(stringList[k],1,whiteSpaceIndex[k]-1) } } stringList }
The weekly ranking table ends up looking like this:
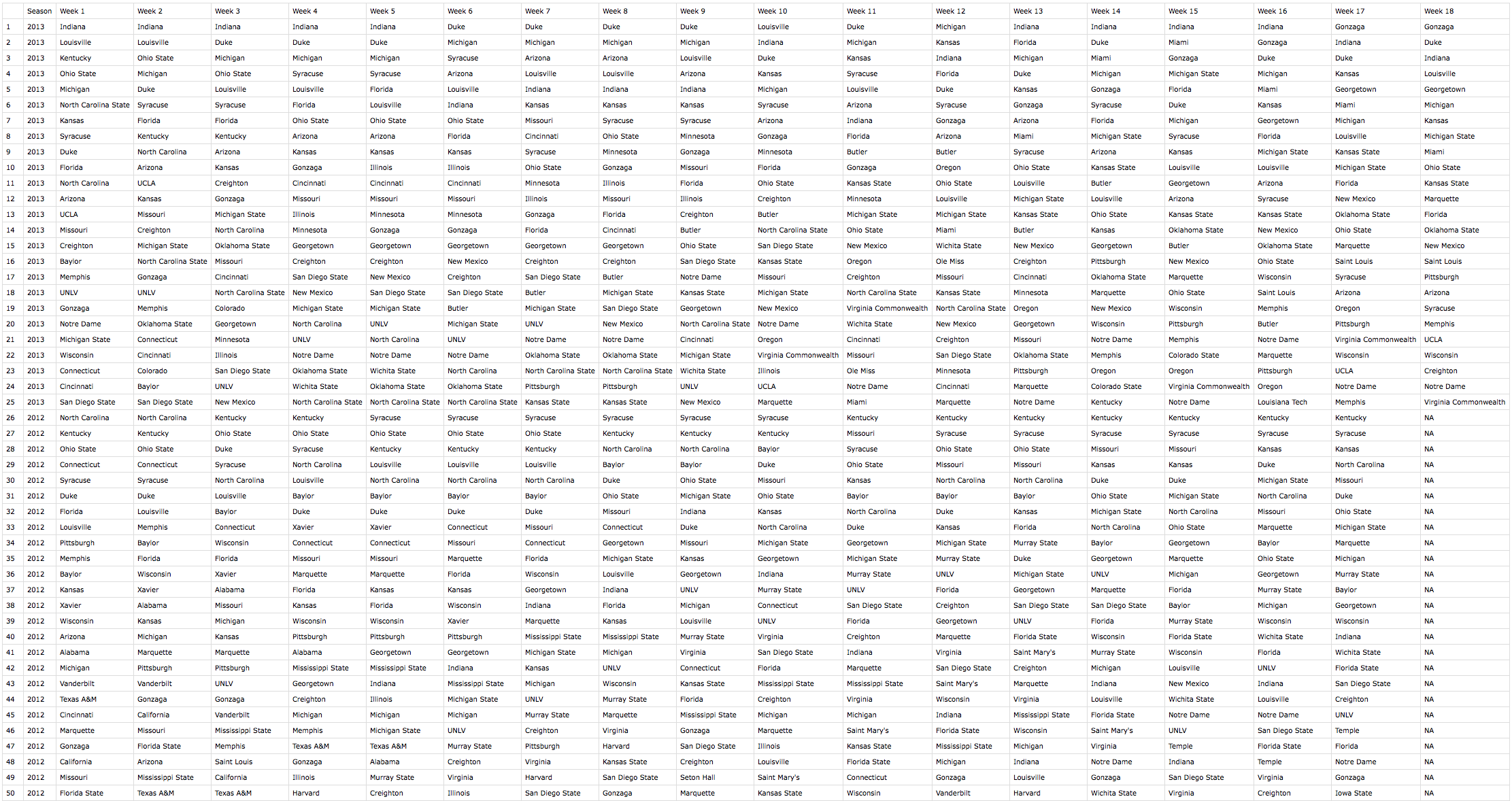
This table is saved purely for reference since all of the meat is in the college quality calculation. College quality is shown below. Again, I kept the “Freq” in for reference so that I could randomly verify the results of a few observations to make sure the code worked properly. As you can see, 43 different teams spent at least one week in the AP Top 25 rankings during 2013.
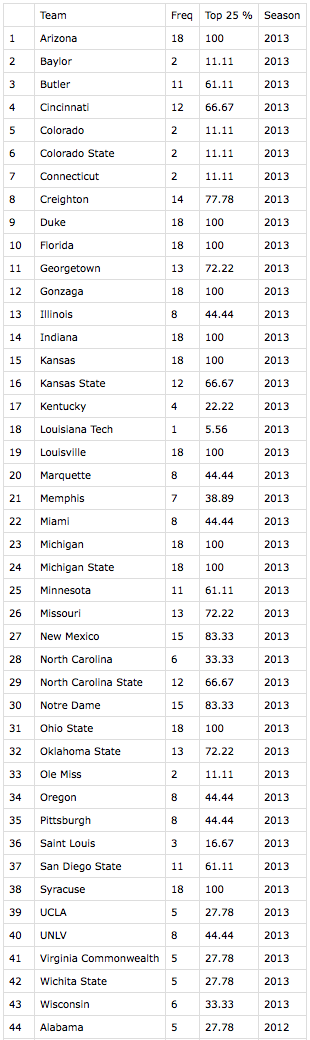
Now that I have this data I can merge it with the master list of players using the school name and season as keys.
