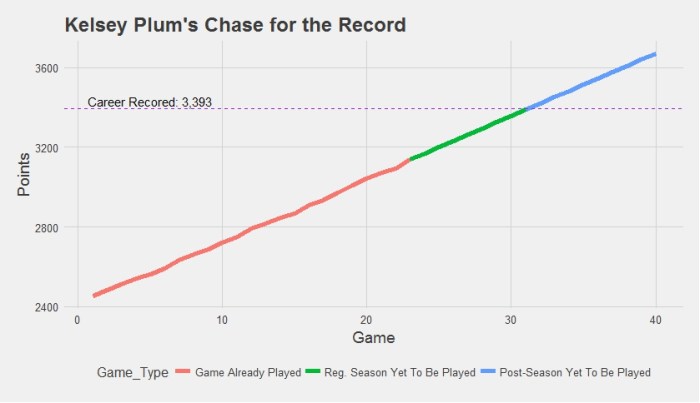
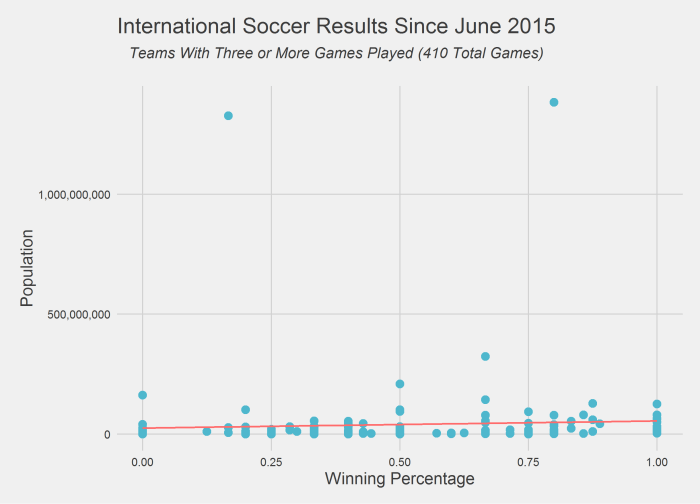
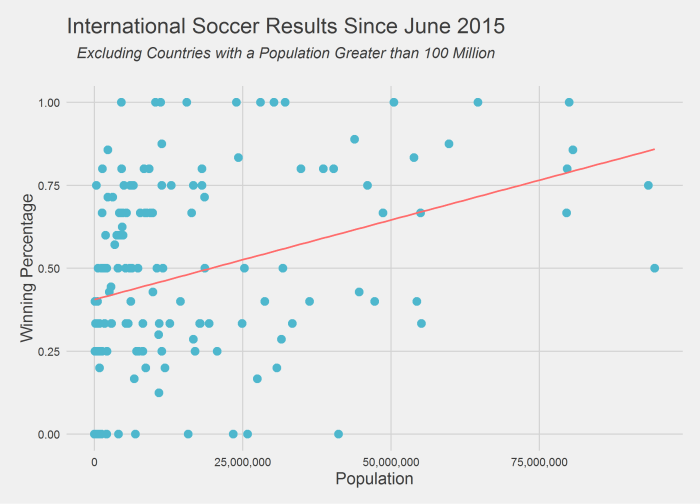
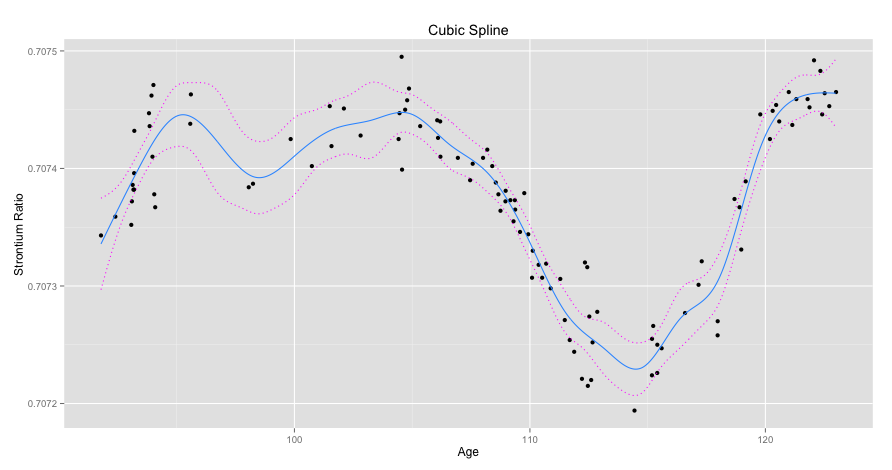
As part of a graduate applied regression course I took we were required to create and present a research question. The top third of the questions were assigned three students, and these groups worked on the project for the last seven weeks of class. I proposed examining the relationship between early career NBA performance and a variety of pre-NBA player attributes.
NBA performance was to be measured using the co-called “Player Efficiency Rating” created by John Hollinger (usually denoted simply “PER”). The PER attempts to combine all of a player’s on-court statistics into a single number, with the NBA average set to 15 every season. The pre-NBA player profile included a variety of advanced statistics measuring shooting, rebounding, steals, assists, and blocks. For some players NBA combine data was also available. The combine data consisted of a variety of body measurements and results from athletic skills tests (such as standing vertical leap).
My team and I worked throughout the quarter and presented our results last week at the class poster presentation. However, I wanted to redo the project on my own time with better data and full control over the data analysis (rather than having to split up the work between there people).
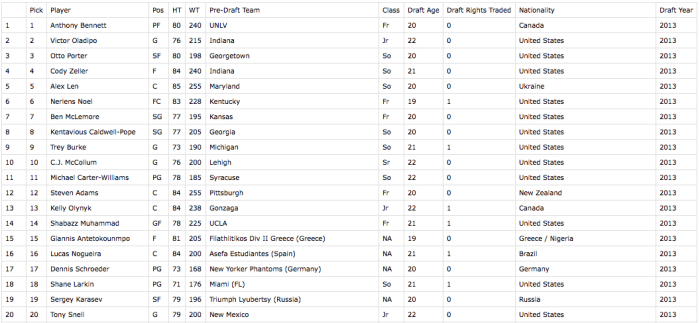
Since this is the second time around I’m much smarter about how to cull, clean, and merge the data efficiently. The first step is to get a master list of players. I’m choosing to use RealGM Basketball’s draft data. It includes both drafted and undrafted players that played in the NBA (or D-league) dating back to 1978. The procedure I used (shown below) works for the modern two-round draft, which started in 1989. However, since college data is only available from the 2002-2003 season, I only went as far back as the 2003 NBA draft.
This dataset includes draft age, an obvious proxy for age a player began his on-court NBA career, something missing from our original dataset. It includes country of birth as well, which would allow a test of the common assertion that foreign players are better shooters. Importantly, this dataset also includes a player’s college name in a format that matches the Associated Press (AP) Top 25 rankings available on ESPN’s website. For instance, depending on the data source the University of Kentucky is sometimes written as “University of Kentucky”, elsewhere simply as “Kentucky”, and occasionally as “UK” (ESPN’s site uses the variant “Kentucky”). I’ve learned that thinking carefully beforehand about how to merge data saves a lot of pain later.
Controlling for the quality of a player’s college basketball program was an unfortunate omission from the original analysis. Because it embodies both the quality of coaching a player received and toughness of competition they faced it may have been a cause of omitted variable bias. For this measure I’ve decided on using the percentage of the season a team was in the AP Top 25 rankings.
To get this master player list I used R’s XML package to scrape the RealGM site. I used try() in conjunction with readHTMLTable() since otherwise my intermittent internet (or other unexpected problems) would cause the for() loop to stop completely. If try() encounters an error I log the page so I can examine it later and pickup any missing data.
After the scrape I examined the data and had to do some simple cleaning. Drafted and undrafted players have slightly different data available so I had to introduce some NA’s for the undrafted players so I could combine the dataframes. I also had to convert the columns from factors to characters or numeric depending on their values. Height, which in its native format as feet-inches (ex. 6-10) needed to be converted to a pure numeric value (I used height in inches). And a few columns had extra characters that needed to be removed.
To convert height I wrote a custom function (shown below). I could have used the R package stringr’s function str_extract() instead of regexpr() and substr(), but for variety (and practice) I went with the less efficient two-line approach. In general, the length of my code could be substantially reduce, but at the cost of readability for others (as well as myself when I revisit the code in the future).
Everything went smoothly aside from a warning that NA’s were introduced by coercion when converting “Weight” to numeric. After a quick search it turns out this was only a problem for a single player, number 1073.
Player 1073 turns out to be Donell Williams from Fayetteville State who went undrafted in 2005 and later played a season in the D-league. I went back to RealGM’s site and confirmed that his weight was indeed marked as “N/A” in the source data.
The next steps will be to merge in the college quality data (from ESPN), a few additional pieces of data I scraped from Basketball-Reference (such as the shooting hand a player uses), all of the NBA combine data (from DraftExpress), and the players’ college and NBA statistics (from RealGM and Basketball-Reference). Each piece of data requires it’s own web scraping and cleaning, which I’ll take up in future posts.
# Load necessary libraries
library(XML)
library(data.table)
library(stringr)
# Initialize variables
round1 <- NULL
round2 <- NULL
drafted <- NULL
undrafted <- NULL
allDraftedPlayers <- NULL
allUndraftedPlayers <- NULL
missedPages <- NULL
seasons <- seq(2013,2003,by=-1)
# Get draft info for drafted and undrafted players
for(i in 1:length(seasons))
{
result <- try(page<-readHTMLTable(paste0(
'http://basketball.realgm.com/nba/draft/past_drafts/', seasons[i])))
if(class(result) == "try-error") { missedPages <- rbind(missedPages,seasons[i]); next; }
round1 <- page[[3]]
round2 <- page[[4]]
drafted <- rbind(round1,round2)
undrafted <- page[[5]]
# Print data for monitoring
print(paste0('http://basketball.realgm.com/nba/draft/past_drafts/', seasons[i]))
print(head(round1))
print(head(round2))
print(head(undrafted))
# Add draft year and combine data
draftYear <- rep(seasons[i], dim(drafted)[1])
print(head(draftYear))
drafted <- cbind(drafted,draftYear)
allDraftedPlayers <- rbind(allDraftedPlayers,drafted)
draftYear <- rep(seasons[i], dim(undrafted)[1])
undrafted <- cbind(undrafted,draftYear)
allUndraftedPlayers <- rbind(allUndraftedPlayers, undrafted)
}
# Drop unused columns
allDraftedPlayers <- allDraftedPlayers[,-c(9,11:12)]
allUndraftedPlayers <- allUndraftedPlayers[,-c(8:9)]
# Add NAs to undrafted players as necessary
length <- length(allUndraftedPlayers[[1]])
allUndraftedPlayers <- cbind(rep(NA, length),allUndraftedPlayers[,c(1:7)],rep(NA,length),
allUndraftedPlayers[,c(8:9)])
# Unify names so rbind can combine datasets
colnames(allUndraftedPlayers)[1] <- "Pick"
colnames(allUndraftedPlayers)[9] <- "Draft RightsTrades"
allPlayers <- rbind(allDraftedPlayers,allUndraftedPlayers)
# Cleanup column names
setnames(allPlayers,c("DraftAge","Draft RightsTrades","draftYear"),
c("Draft Age","Draft Rights Traded","Draft Year"))
# Convert columns from factors to character and numeric as necessary
allPlayers[,-3] <- data.frame(lapply(allPlayers[,-3], as.character),
stringsAsFactors=FALSE)
allPlayers[,c(5,8)] <- data.frame(lapply(allPlayers[,c(5,8)], as.numeric),
stringsAsFactors=FALSE)
# Add dummy if player was traded on draft day
traded <- allPlayers[[9]]
allPlayers[which(regexpr("[a-zA-Z]+",traded) != -1), 9] <- 1
allPlayers[which(allPlayers[[9]] != 1), 9] <- 0
# Get rid of extra characters in class (mostly astricks)
allPlayers[[7]] <- str_extract(allPlayers[[7]],"[a-zA-Z]+")
allPlayers[[7]] <- gsub("DOB",NA,allPlayers[[7]])
# Convert height to inches from feet-inches format
allPlayers[[4]] <- convertHeight(allPlayers[[4]])
# Function for converting height
convertHeight <- function(x) {
feet <- substr(x,1,1)
inches <- regexpr("[0-9]+$",x)
inches <- substr(x, inches, inches + attr(inches,"match.length"))
height <- as.numeric(feet)*12 + as.numeric(inches)
return(height)
}
write.csv(allPlayers,file="~/.../Draft Info/All Drafted Players 2013-2003.csv")
R Highlighting created by Pretty R at inside-R.org
The result is to take this:
And transform it into this:

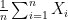



 and moves one unit to the left with probability
and moves one unit to the left with probability 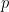 and moves one unit to the right with probability
and moves one unit to the right with probability 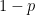 . What is the expected position
. What is the expected position ![\mathbb{E}[X_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002) of the particle after
of the particle after 
![n=0: \quad \mathbb{E}[X_0] = z_i](https://s0.wp.com/latex.php?latex=n%3D0%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_0%5D+%3D+z_i+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = (z_i - 1)p + (z_i + 1)(1 - p)](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+%28z_i+-+1%29p+%2B+%28z_i+%2B+1%29%281+-+p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = z_{i}p - p + z_i + 1 - z_{i}p - p](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+z_%7Bi%7Dp+-+p+%2B+z_i+%2B+1+-+z_%7Bi%7Dp+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = z_i + 1 - 2p](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+z_i+%2B+1+-+2p+&bg=ffffff&fg=000000&s=0&c=20201002)
 our position is now the result from
our position is now the result from  ,
,  .
.![n=2: \quad \mathbb{E}[X_2] = (z_i + 1 - 2p - 1)p + (z_i + 1 - 2p + 1)(1 - p)](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+%28z_i+%2B+1+-+2p+-+1%29p+%2B+%28z_i+%2B+1+-+2p+%2B+1%29%281+-+p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=2: \quad \mathbb{E}[X_2] = z_{i}p - 2p^2 + Z_i - 2p + 2 - z_{i}p + 2p^2 - 2p](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+z_%7Bi%7Dp+-+2p%5E2+%2B+Z_i+-+2p+%2B+2+-+z_%7Bi%7Dp+%2B+2p%5E2+-+2p&bg=ffffff&fg=000000&s=0&c=20201002)
![n=2: \quad \mathbb{E}[X_2] = z_i + 2(1 - 2p)](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+z_i+%2B+2%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_n] = z_i + n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+%3D+z_i+%2B+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002) . But we can prove this formally through induction. We’ve already done our base case, so let’s now do the induction step. We will assume that
. But we can prove this formally through induction. We’ve already done our base case, so let’s now do the induction step. We will assume that  .
.![\mathbb{E}[X_{n+1}] = (z_i + n(1 - 2p) - 1)p + (z_i + n(1 - 2p) + 1)(1 - p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+%28z_i+%2B+n%281+-+2p%29+-+1%29p+%2B+%28z_i+%2B+n%281+-+2p%29+%2B+1%29%281+-+p%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = (z_i + n - 2pn - 1)p + (z_i + n - 2pn + 1)(1 - p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+%28z_i+%2B+n+-+2pn+-+1%29p+%2B+%28z_i+%2B+n+-+2pn+%2B+1%29%281+-+p%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = z_{i}p + pn - 2p^{2}n - p + z_i + n - 2pn + 1 -z_{i}p - pn + 2p^{2}n - p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+z_%7Bi%7Dp+%2B+pn+-+2p%5E%7B2%7Dn+-+p+%2B+z_i+%2B+n+-+2pn+%2B+1+-z_%7Bi%7Dp+-+pn+%2B+2p%5E%7B2%7Dn+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = - p + z_i + n - 2pn + 1 - p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+-+p+%2B+z_i+%2B+n+-+2pn+%2B+1+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = z_i + (n + 1)(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+z_i+%2B+%28n+%2B+1%29%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_n] = n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+%3D+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002) .
. . This would mean we have an equal chance of moving left or moving right. Over the long run we would expect our final position to be exactly where we started. Plugging in
. This would mean we have an equal chance of moving left or moving right. Over the long run we would expect our final position to be exactly where we started. Plugging in 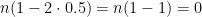 . Just as we expected! What if
. Just as we expected! What if  ? This means we only move to the left. Plugging
? This means we only move to the left. Plugging 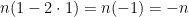 . This makes sense! If we can only move to the left then after
. This makes sense! If we can only move to the left then after  all distributed uniformly,
all distributed uniformly, 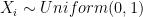 . We want to find the expected value of
. We want to find the expected value of ![\mathbb{E}[Y_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002) where
where  .
.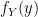 and we do so in the usual way, by first finding the Cumulative Distribution Function (CDF) and taking the derivative:
and we do so in the usual way, by first finding the Cumulative Distribution Function (CDF) and taking the derivative:
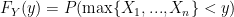
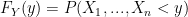

 ‘s are in fact independent. Thanks to Ryan for helping me see that by definition:
‘s are in fact independent. Thanks to Ryan for helping me see that by definition:
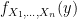 is a unit
is a unit 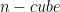 with area
with area  equal to
equal to 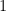 . In other words
. In other words  . Our equation then simplifies:
. Our equation then simplifies: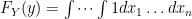
![F_Y(y) = \int dx_1 \dots \int dx_n = [F_X(y)]^n](https://s0.wp.com/latex.php?latex=F_Y%28y%29+%3D+%5Cint+dx_1+%5Cdots+%5Cint+dx_n+%3D+%5BF_X%28y%29%5D%5En+&bg=ffffff&fg=000000&s=0&c=20201002) where
where 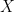 here is a generic random variable, by symmetry (all
here is a generic random variable, by symmetry (all  we can find
we can find ![f_Y(y) = \frac{d}{dy}F_Y(y) = \frac{d}{dy}[F_X(y)]^n](https://s0.wp.com/latex.php?latex=f_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7DF_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7D%5BF_X%28y%29%5D%5En+&bg=ffffff&fg=000000&s=0&c=20201002)
![f_Y(y) = n[F_X(y)]^{n-1}f_X(y)](https://s0.wp.com/latex.php?latex=f_Y%28y%29+%3D+n%5BF_X%28y%29%5D%5E%7Bn-1%7Df_X%28y%29+&bg=ffffff&fg=000000&s=0&c=20201002) by the chain rule.
by the chain rule. of a
of a  is
is  for
for ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . And by extension the CDF
. And by extension the CDF 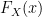 for a
for a 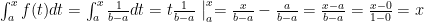 .
.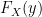 not
not 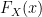 meaning we simply replace the
meaning we simply replace the  we just derived with
we just derived with 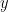 as we would in any normal function) we have:
as we would in any normal function) we have: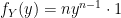
![\mathbb{E}[Y] = \int_{y\in A}yf_Y(y)dy = \int_0^1 yny^{n-1}dy = n\int_0^1 y^{n}dy = n\bigg[\frac{1}{n+1}y^{n+1}\bigg]_0^1 = \frac{n}{n+1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%5Cint_%7By%5Cin+A%7Dyf_Y%28y%29dy+%3D+%5Cint_0%5E1+yny%5E%7Bn-1%7Ddy+%3D+n%5Cint_0%5E1+y%5E%7Bn%7Ddy+%3D+n%5Cbigg%5B%5Cfrac%7B1%7D%7Bn%2B1%7Dy%5E%7Bn%2B1%7D%5Cbigg%5D_0%5E1+%3D+%5Cfrac%7Bn%7D%7Bn%2B1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
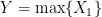 (which is simply
(which is simply  ;
; 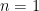 in this case) we get
in this case) we get  . This makes sense! If
. This makes sense! If  is just a uniform random variable on the interval
is just a uniform random variable on the interval 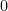 to
to  which is exactly what we got.
which is exactly what we got. . This also makes sense! If we take the maximum of 1 or 2 or 3
. This also makes sense! If we take the maximum of 1 or 2 or 3 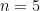 (thanks to the fantastic
(thanks to the fantastic