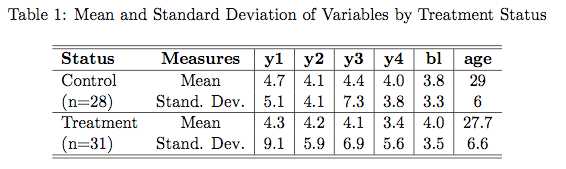
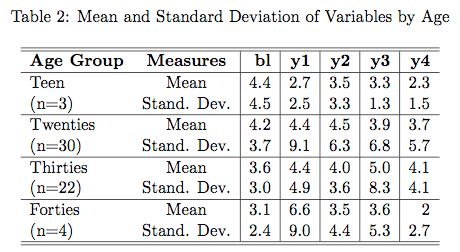
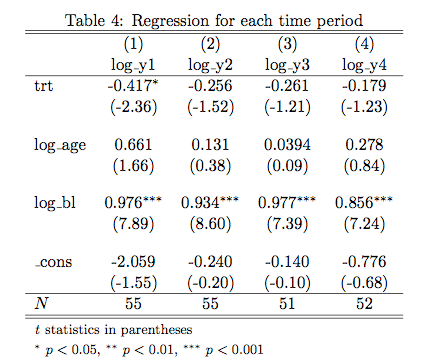
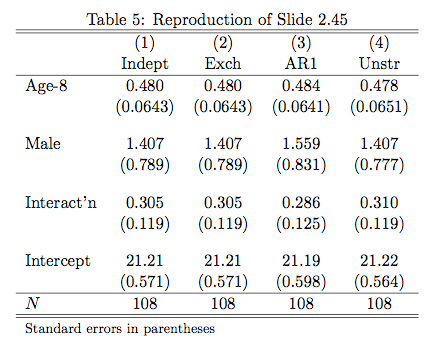
While I was researching some sections for my thesis I found some literature on the spread of new technology in developing countries. I had the idea of using the World Bank Living Standards Measurement Survey (LSMS) to do a simple logistic regression to investigate the determinants of modern seed use. The literature suggests there are several important factors uptake of new These are things like education, access to credit, receipt of a voucher, and risk aversion.
The LSMS wasn’t designed for this sort of analysis so the results will be less than perfect. Nonetheless, I wanted to get experience working with a complex dataset to do a real analysis. And despite it’s shortcomings the LSMS does include a host of information that can be used.
One general challenge with the LSMS is that it’s broken down into 20+ files, one for each section of the survey. Some files are aggregated at the household level, others at the level of each household member, and still others at the level of a house’s many farm plots.
The analysis I wanted to do also included creating a number of aggregated and dummy variables, and it took some time to verify I was doing this correctly (ex. making sure I kept track of missing data). After I merged the data I did a visual test using histograms to see if the demographic profile of those with and without data for modern seed use was similar. I was surprised to find that the missing data seemed to be roughly missing at random.
/************************************************
// James McCammon
// LSMS Modern Seed Use Logistic Regression
// Version 1
// Project started 3 March 2014
*************************************************/
// Set working directory
//cd "C:\Users\Public\Documents\LSMS Files\Specification"
//*******************************************************************
//-------------Create and Merge HH_SEC_A and HH_SEC_B --------------
//********************************************************************
// Sec_B
use HH_SEC_B
// Rename variables
rename indidy2 HH_Member_No
rename hh_b04 Age
rename hh_b02 Sex
rename hh_b05 HH_Status
// Subset data
keep y2_hhid HH_Member_No Age Sex HH_Status
// Decode HH_Status for clarity. This allows reference
// to HH_Status as "Head" not 1.
decode HH_Status, generate(HH_Status_Str)
drop HH_Status
rename HH_Status_Str HH_Status
// Generate new variables
by y2_hhid: egen Fam_Size = max(HH_Member_No)
gen Head_Age = Age if HH_Status == "HEAD"
gen Head_Sex = Sex if HH_Status == "HEAD"
// Recode Sex so that Male = 0, Female = 1
// Females get higher number because they're better
recode Head_Sex (1=0)
recode Head_Sex (2=1)
// Save file
save HH_SEC_B_Reduced, replace
// Merge Sec_A and Sec_B
use HH_SEC_A.dta
keep y2_hhid y2_weight y2_rural clusterid strataid region district ward
save HH_SEC_A_Redux, replace
merge 1:m y2_hhid using HH_SEC_B_Reduced
drop _merge
sort y2_hhid HH_Member_No
save Log_Reg_Data, replace
//********************************************
//-------------Merge in HH_SEC_C--------------
//********************************************
// Sec_C
use HH_SEC_C
// Rename variables
rename indidy2 HH_Member_No
rename hh_c02 Read
rename hh_c07 Edu_Level
// Subset data
keep y2_hhid HH_Member_No Read Edu_Level
// Save data
save HH_SEC_C_Reduced, replace
// Merge Sec_C with main dataset
use Log_Reg_Data
merge 1:1 y2_hhid HH_Member_No using HH_SEC_C_Reduced
drop _merge
sort y2_hhid HH_Member_No
// Generate variable for highest level of education in the house
// These values can be found in the online codebook for LSMS data.
// Primary School
gen Edu_House_Temp = 1 if Edu_Level >= 11 & Edu_Level <= 20
// Secondary School
replace Edu_House_Temp = 2 if Edu_Level >= 21 & Edu_Level <= 34
// University
replace Edu_House_Temp = 3 if Edu_Level >= 41 & Edu_Level <= 45
by y2_hhid: egen Edu_House = max(Edu_House) if !missing(Edu_House)
drop Edu_House_Temp
// Generate variable for highest level of education of the head of household
// These values can be found in the online codebook for LSMS data.
// Primary School
gen Edu_Head = 1 if HH_Status == "HEAD" & Edu_Level >= 11 & Edu_Level <= 20
// Secondary School
replace Edu_Head = 2 if HH_Status == "HEAD" & Edu_Level >= 21 & Edu_Level <= 34
// University
replace Edu_Head = 3 if HH_Status == "HEAD" & Edu_Level >= 41 & Edu_Level <= 45
// Generate variable if anyone in the house speaks English
gen Eng_House = cond(missing(Read),.,cond(Read == 2 | Read == 3, 1, 0))
// Generate variable if the Head speaks English
gen Eng_Head = cond(missing(Read),.,cond(Read == 2 | Read == 3, 1, 0)) ///
if HH_Status =="HEAD"
// Save file
save Log_Reg_Data, replace
//********************************************
//-------------Merge in HH_SEC_G--------------
//********************************************
// Sec G
use HH_SEC_G
// Rename variables
rename indidy2 HH_Member_No
rename hh_g01 Anwsering_For_Self_2
rename hh_g04 Current_Welfare
rename hh_g05 Three_Years_Ago_Welfare
rename hh_g06 Ten_Years_Ago_Welfare
// Subset data
keep y2_hhid HH_Member_No Anwsering_For_Self_2 ///
Current_Welfare Three_Years_Ago_Welfare Ten_Years_Ago_Welfare
duplicates drop
// Create variable for worst household memeber perception of current welfare
by y2_hhid: egen Worst_Wel_Cur = max(Current_Welfare) if Current_Welfare != 8
// Create variable for best household memeber perception of current welfare
by y2_hhid: egen Best_Wel_Cur = min(Current_Welfare) if Current_Welfare != 8
// Create variable for median household memeber perception of current welfare
by y2_hhid: egen Med_Wel_Cur = median(Current_Welfare) if Current_Welfare != 8
// Create variable for worst household memeber perception of welfare 3 years ago
by y2_hhid: egen Worst_Wel_3 = max(Three_Years_Ago_Welfare) if Three_Years_Ago_Welfare != 8
// Create variable for best household memeber perception of welfare 3 years ago
by y2_hhid: egen Best_Wel_3 = min(Three_Years_Ago_Welfare) if Three_Years_Ago_Welfare != 8
// Create variable for median household memeber perception of current welfare
by y2_hhid: egen Med_Wel_3 = median(Three_Years_Ago_Welfare) if Three_Years_Ago_Welfare != 8
// Create variable for worst household memeber perception of welfare 10 years ago
by y2_hhid: egen Worst_Wel_10 = max(Ten_Years_Ago_Welfare) if Ten_Years_Ago_Welfare != 8
// Create variable for best household memeber perception of welfare 10 years ago
by y2_hhid: egen Best_Wel_10 = min(Ten_Years_Ago_Welfare) if Ten_Years_Ago_Welfare != 8
// Create variable for median household memeber perception of current welfare
by y2_hhid: egen Med_Wel_10 = median(Ten_Years_Ago_Welfare) if Ten_Years_Ago_Welfare != 8
// Save file
save HH_SEC_G_Reduced, replace
// Main dataset
use Log_Reg_Data
merge 1:1 y2_hhid HH_Member_No using HH_SEC_G_Reduced
drop _merge
save Log_Reg_Data, replace
//****************************************
//-------------Collapse Data--------------
//****************************************
// All further data merges do not use HH Member ID
// so it is appropriate to collapse all data to HH level
#delimit ;
collapse y2_weight y2_rural clusterid strataid region district ward
Head_Age Head_Sex Fam_Size Med_Wel_Cur Med_Wel_3 Med_Wel_10
Eng_House Eng_Head Edu_House Edu_Head, by(y2_hhid);
#delimit cr
// Cleanup Eng_House
replace Eng_House = 1 if Eng_House > 0 & Eng_House <= 1
// Label education levels
label define Education_Label 1 "Primary" 2 "Secondary" 3 "University"
label values Edu_House Education_Label
label values Edu_Head Education_Label
// Label English levels
label define English_Label 1 "English" 0 "Other"
label values Eng_House English_Label
label values Eng_Head English_Label
// Label Head_sex
label define Sex_Label 0 "Male" 1 "Female"
label values Head_Sex Sex_Label
// Save file
save Log_Reg_Data, replace
//********************************************
//-------------Merge in HH_SEC_I--------------
//********************************************
// Sec I
use HH_SEC_I1
// Rename variables
rename hh_i01 Food_Insecure
// Subset data
keep y2_hhid Food_Insecure
// Save file
save HH_SEC_I1_Reduced, replace
// Merge with main dataset
use Log_Reg_Data
merge 1:1 y2_hhid using HH_SEC_I1_Reduced
drop _merge
save Log_Reg_Data, replace
//********************************************
//-------------Merge in AG_SEC3A--------------
//********************************************
// Sec 3A
use AG_SEC3A
// Rename variables
rename ag3a_64 Credit
// Subset data
keep y2_hhid Credit
// Cleanup Credit for long rainy season
rename Credit Credit_L
label values Credit_L
recode Credit_L (2=0)
collapse Credit_L, by(y2_hhid)
replace Credit_L = 1 if Credit_L > 0 & Credit_L <= 1
// Save file
save AG_SEC3A_Reduced, replace
// Merge with main dataset
use Log_Reg_Data
merge 1:1 y2_hhid using AG_SEC3A_Reduced
drop _merge
save Log_Reg_Data, replace
//********************************************
//-------------Merge in AG_SEC3B--------------
**********************************************
// Sec 3B
use AG_SEC3B
// Rename variables
rename ag3b_64 Credit
// Subset data
keep y2_hhid Credit
// Generate and cleanup Credit for short rainy season
rename Credit Credit_S
label values Credit_S
recode Credit_S (2=0)
collapse Credit_S, by(y2_hhid)
replace Credit_S = 1 if Credit_S > 0 & Credit_S <= 1
// Save file
save AG_SEC3B_Reduced, replace
// Merge with main dataset
use Log_Reg_Data
merge 1:1 y2_hhid using AG_SEC3B_Reduced
drop _merge
save Log_Reg_Data, replace
//********************************************
//-------------Merge in AG_SEC4A--------------
//********************************************
// Sec 4A
use AG_SEC4A
// Rename variables
rename ag4a_20 Voucher
rename ag4a_23 Modern_Seed
// Subset data
keep y2_hhid Voucher Modern_Seed
// Generate Voucher_L for long rainy season
rename Voucher Voucher_L
recode Voucher_L (2=0)
// Generate Modern_Seed_L for long rainy season
rename Modern_Seed Modern_Seed_L
recode Modern_Seed_L (1=0)
recode Modern_Seed_L (2=1)
// collapse data
collapse Voucher_L Modern_Seed_L, by(y2_hhid)
// Cleanup Voucher
replace Voucher_L = 1 if Voucher_L > 0 & Voucher_L <= 1
// Cleanup Modern_Seed
replace Modern_Seed_L = 1 if Modern_Seed_L > 0 & Modern_Seed_L <= 1
// Save file
save AG_SEC4A_Reduced, replace
// Merge with main dataset
use Log_Reg_Data
merge 1:1 y2_hhid using AG_SEC4A_Reduced
drop _merge
save Log_Reg_Data, replace
//********************************************
//-------------Merge in AG_SEC4B--------------
//********************************************
// Sec 4B
use AG_SEC4B
// Rename variables
rename ag4b_20 Voucher
rename ag4b_23 Modern_Seed
// Subset data
keep y2_hhid Voucher Modern_Seed
// Generate Voucher for short rainy season
rename Voucher Voucher_S
recode Voucher_S (2=0)
// Generate Modern_Seed for short rainy season
rename Modern_Seed Modern_Seed_S
recode Modern_Seed_S (1=0)
recode Modern_Seed_S (2=1)
// Collapse data
collapse Voucher_S Modern_Seed_S, by(y2_hhid)
// Cleanup Voucher
replace Voucher_S = 1 if Voucher_S > 0 & Voucher_S <= 1
// Cleanup Modern_Seed_S
replace Modern_Seed_S = 1 if Modern_Seed_S > 0 & Modern_Seed_S <= 1
// Save file
save AG_SEC4B_Reduced, replace
// Merge with main dataset
use Log_Reg_Data
merge 1:1 y2_hhid using AG_SEC4B_Reduced
drop _merge
save Log_Reg_Data, replace
//*********************************************************
//-------------Collate Rainy Season Data-------------------
***********************************************************
// Collate Credit
// Generate variable if the house received credit during
// either the long or short rainy seasons
gen Credit = cond(Credit_L == 1 | Credit_S == 1, 1, 0)
replace Credit = . if Credit_L == . & Credit_S == .
// Label Credit
label define Credit_Label 1 "Yes" 0 "No"
label values Credit Credit_Label
// Drop long and rainy season specific variables
drop Credit_S Credit_L
// Collate Voucher
// Generate variable if the house received a seed voucher
// during either the long or short rainy seasons
gen Voucher = cond(Voucher_L == 1 | Voucher_S == 1, 1, 0)
replace Voucher = . if Voucher_L == . & Voucher_S == .
// Label Voucher
label define Voucher_Lavel 1 "Yes" 0 "No"
label values Voucher Voucher_Label
// Drop long and short rainy season specific variables
drop Voucher_L Voucher_S
// Collate Modern_Seed
// Generate variable if the house planted modern seed on any plot
// during either the long or short rainy seasons
gen Modern_Seed = cond(Modern_Seed_L == 1 | Modern_Seed_S == 1,1,0)
replace Modern_Seed = . if Modern_Seed_L == . & Modern_Seed_S == .
// Label Modern_Seed
label define Seed_Label 1 "Modern" 0 "Traditional"
label values Modern_Seed Seed_Label
// Drop long and short rainy season specific variables
drop Modern_Seed_L Modern_Seed_S
// Save data
save Log_Reg_Data, replace
//******************************************************
//-------------Check Balance Visually-------------------
//******************************************************
// Generate variable based on whether or not there was any response
// to the use of modern seed during either the long or short rainy
// seasons.
gen Balance_Test = cond(Modern_Seed == 1 | Modern_Seed == 0, 1, 0)
save Log_Reg_Data, replace
// Generate histograms
graph drop _all
hist Head_Age, by(Balance_Test) name(Age) title("Age of Head")
hist Head_Sex, by(Balance_Test) name(Sex) title("Sex of Head")
hist Fam_Size, discrete by(Balance_Test) name(Fam_Size) title("Size of Family")
hist Med_Wel_Cur, discrete by(Balance_Test) name(Med_Wel_Cur) title("Med Fam Welfare") subtitle("Current")
hist Med_Wel_3, discrete by(Balance_Test) name(Med_Wel_3) title("Med Fam Welfare") subtitle("3 Years Ago")
hist Med_Wel_10, discrete by(Balance_Test) name(Med_Wel_20) title("Med Fam Welfare)") subtitle("10 Years Ago")
hist Edu_House, by(Balance_Test) name(Edu_House) title("Highest Education of House")
hist Edu_Head, by(Balance_Test) name(Edu_Head) title("Highest Education of Head")
hist Food_Insecure, by(Balance_Test) name(Food_Insecure) title("House Food Security")
hist Credit, by(Balance_Test) name(Credit) title("Credit Receipt")
hist Voucher, by(Balance_Test) name(Voucher) title("Voucher Receipt")
//*******************************************
//-------------Diagnostics-------------------
//*******************************************
/*
When merging in HH_SEC_G there was a mismatch in the size
of the two files. I ran these diagnostics:
duplicates report
duplicates example
duplicates tag, generate(dup)
list if dup==1
duplicates drop
These reports showed that observation 15195 was a duplicate.
I then dropped it.
*/
Formatted By Econometrics by Simulation