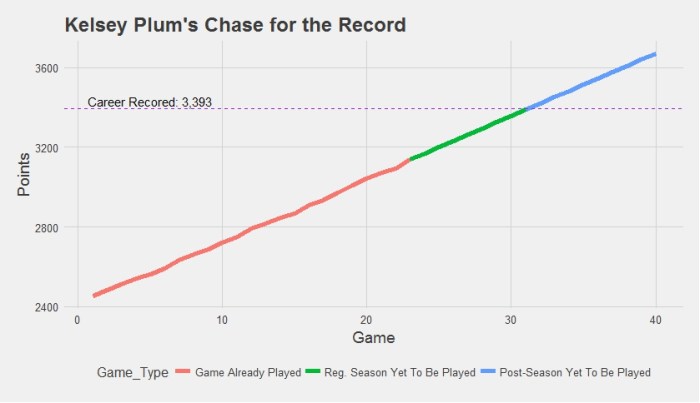
Unless a miracle occurs the UConn Women’s Basketball team will soon win their fourth championship in a row in an undefeated season when they beat Syracuse on Tuesday night. This will be their sixth championship since 2009. If they lose it will be one of the greatest upsets in the history of team sports.
Where does their recent dominance rank in the all-time history of sports? I put together this short survey.
The UNC women’s soccer team is — as far as I know — the most dominate team in the history of sports, collegiate or professional (at least in the U.S.), Harlem Globetrotters aside. They’ve been consistently dominate now for three decades and won 22 of the 36 NCAA National Championships. Of course U.S. women’s professional soccer has also been dominate the past 15 years with numerous World Cup and Olympic gold medal wins as well as being ranked No. 1 continuously from March 2008 to December 2014. En Espana, Barcelona has created a dominant European futbol team.
The UCLA men’s basketball team of the 1960s and 1970s won seven straight national titles under the famous John Wooden. The Iowa Hawkeyes men’s wrestling team also had an amazing run of dominance, especially throughout the 1990s. My alma matter, the University of Washington, has won five consecutive national crew championship in the men’s varsity eight. Jointly, the University of Minnesota and University of Minnesota Duluth have been dominating Women’s Ice Hockey since 2001, winning a combined 10 National Championships.
The University of Arkansas won eight consecutive national Track & Field Championships on the men’s side throughout the 1990s, while the LSU women won 11 championships in a row in the ’80s and ’90s (wow!). Swimming and diving national championships seem to come in bundles. Since 1937 only 13 different men’s teams have won national championships and many were back to back or three-peats. The women’s side is equally streaky. By the way, there are quite a few schools with swimming and diving programs.
Of course Alabama’s football team has been quite successful over the past seven years, winning four FBS championships in a rather competitive sport that has recently instituted a playoff system (Alabama has won one out of two of those).
What I’ve listed so far have been Division I-A programs only. Certainly some smaller college programs have seen dominance. And of course there are dominant high school teams as well. St. Anthony’s in New Jersey has won 27 boys’s basketball state titles in the past 39 years, for instance. Maryville Tennessee’s high school football team has gone 145-5 and won seven state titles in recent memory. Cheryl Miller, perhaps the greatest female basketball player of all time (and yes, brother of Reggie Miller), led her high school team to a record of 132-4 from ’78-’82 and along the road scored 105 points in a single game. Reggie Miller often recalls the night he found out about his sister’s scoring outburst. He had just scored 39 points and was pretty proud of himself until his sister reported back that she had more than doubled that total. I recall hearing about several boy’s wrestling champions with perfect high school careers. Here is one example.
A number of professional teams have had long periods of dominance. Chinese women’s diving has been extremely dominant recently. The New York Baseball Yankees have won 27 World Championships and 40 American League pennants over the past 100 years, with many of these coming over the 45-year period between 1920 and 1965. I’m aware that Russian hockey and gymnastics teams were quite great in their prime, perhaps still so.
The Boston Celtics won eight straight World Championships throughout the 1960s, helping Bill Russell win a total of 11 championship rings during his career. Indeed, Bill Russell is sometimes considered the greatest winner in the history of team sports and as such when LeBron James left Russell off of his theoretical “Mount Rushmore of the NBA” Russell was able to respond with this amazing quote regarding his own athletic success:
Hey, thank you for leaving me off your Mount Rushmore. I’m glad you did. Basketball is a team game, it’s not for individual honors. I won back-to-back state championships in high school, back-to-back NCAA championships in college. I won an NBA championship my first year in the league, an NBA championship in my last year, and nine in between. That, Mr. James, is etched in stone.
Individual athletics has also seen sportsmen and women that have been consistently dominant. Tiger Woods, Usain Bolt, Sean White, and Michael Phelps have all had multi-year stretches of dominance in recent memory. At least one of them was just featured in an inspiring commercial. Of course there were many dominant athletes in each of these sports before the current incarnations (Jack Nicklaus, Carl Lewis, Mark Spitz). Eric Heiden won five speed skating medals in the Lake Placid Olympics, starting with the 500 meters and ending with the 10,000 meters. I once watched a documentary in which this feat was compared with a single athlete winning both the 100 meter dash and the mile. Tony Hawk helped usher in skateboarding as a professional sport and was dominant while doing so. Chris Sharma did the same with rock climbing. Rich Froning Jr. has had early success in the burgeoning activity of crossfit as a sport, winning the title of “Fittest Man on Earth” four times since 2011.
Anderson Silva had a long run of dominance in MMA and you’ve certainly heard of some of boxing’s all-time greats. Ronda Rousey garnered fame for her win streak until she was beaten just this year; she also appeared in the horrible movie version of HBO’s Entourage, though I liked her performance. If you’ve ever been to the ballet you know it can be extremely athletic. How’s that for an inspirational commercial? Perhaps it’s time we consider ballet a sport?
And then there is this horse.
Tennis has a history of dominant players including two current players: Novak Djokovic and Serena Williams. Serena is already generally considered the best female player of all time and Novak may end up the greatest men’s player before his career is over. Previous generations included Steffi Graf, Martina Navratilova, Roger Federer, Pete Sampras, and many others. Each was extremely dominant during their prime. For example, during his prime Roger Federer held the Number 1 position for 302 consecutive weeks, reached 23 consecutive Grand Slam tournament semifinals and won five consecutive times both at Wimbledon and the US Open and three out of four at the Australian open.
Perhaps a dark-horse contender for most dominate athlete is Kelly Slater, the American professional surfer who won five consecutive titles from ’94 to ’98. There are a number of articles suggesting he may be the greatest male athlete of all time. He won his first title at age 20 and his last at age 39 (and he’s still surfing competitively!). Talk about longevity. Imagine if Kobe Bryant was leading the Lakers to a title this year or if Peyton Manning had been truly great in the Bronco’s Super Win and you have some idea of what Kelly Slater has accomplished. (Yes, I realize surfing is a non-contact sport. Or is it?).
What have I forgotten? Surely there must be a lot. Certainly, this list is too U.S. centric.
But back to the question at hand. There have been many conversations about whether the UConn women’s dominance is bad for women’s college basketball. It has been suggested by some that this is a sexist argument, but I disagree. If Kentucky’s men’s basketball team was on the verge of winning its fourth straight NCAA tournament there would certainly be discussion about their dominance, perhaps around allegations of illegal recruiting or steroid use or at the very least a discussion about reforming the current one-and-done system.
And the question of whether a team can be too dominate is not new. Indeed, many professional sports are structured specifically to provide — or at least attempt to provide — equity among smaller and larger markets. Think of the draft or salary caps. Of course, in individual sports we fear dominance less because we know natural aging will create a new wave of competition in a few years time, or if we’re talking about individual college sports the athlete will simply graduate.
But we also understand that long-term equilibrium can occur where success begets success. College players, shamefully, are not paid in dollars so the next best thing is to be paid in wins. UConn seems to be the central bank in that category.
On the other hand — and as the list above eludes to — dominance is not unique to the UConn women. In fact, in the grand scheme of things they aren’t so dominate after all. But in some sports we’re use to seeing new champions more often than in others, if only because most people in the U.S. only follow the big four. We’re use to seeing new men’s champions every year to be sure, even if they’re all generally from the same group of ten or twenty teams year after year. So it really stands out when the same women’s team wins repeatedly regardless of where they stand in the broader historical spectrum.
The best thing, it seems, would be for Syracuse to beat UConn and put the whole matter to rest.