Larry Wasserman presents an interesting simulation in Problem 11, Chapter 3 of All of Statistics. The problem asks you to simulate the stock market by modeling a simple random walk. With probability 0.5 the price of the stock goes down $1 and with probability 0.5 the stock prices goes up $1. You may recognize this as the same setup in our two simple random walk examples modeling a particle on the real line.
This simulation is interesting because Wasserman notes that even with an equal probability of the stock moving up and down we’re likely to see patterns in the data. I ran some simulations that modeled the change in stock price over the course of 1,000 days and grabbed a couple of graphs to illustrate this point. For example, look at the graph below. It sure looks like this is a stock that’s tanking! However, it’s generated with the random walk I just described.
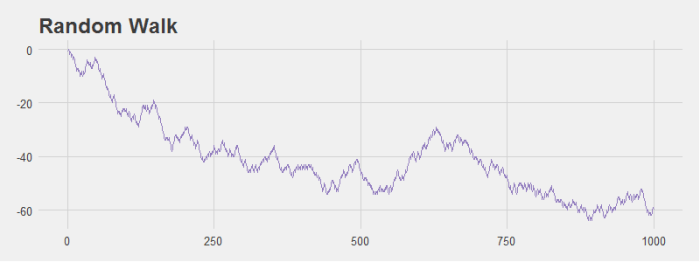
Even stocks that generally hover around the origin seem to have noticeable dips and peaks that look like patterns to the human eye even though they are not.
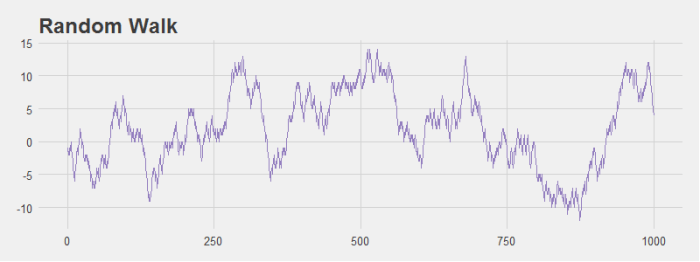
If we run the simulation multiple times it’s easy to see that if you consider any single stock it’s not so unlikely to get large variations in price (the light purple lines). However, when you consider the average price of all stocks, there is very little change over time as we would expect (the dark purple line).

Here is the R code to calculate the random walk and generate the last plot:
################################################################ # R Simulation # James McCammon # 2/20/2017 ################################################################ # This script goes through the simulation of changes in stock # price data. # Load plotting libraries library(ggplot2) library(ggthemes) library(reshape2) # # Simulate stock price data with random walk # n = 1000 # Walk n steps p = .5 # Probability of moving left trials = 100 # Num times to repeate sim # Run simulation rand_walk = replicate(trials, cumsum(sample(c(-1,1), size=n, replace=TRUE, prob=c(p,1-p)))) # # Prepare data for plotting # all_walks = melt(rand_walk) avg_walk = cbind.data.frame( 'x' = seq(from=1, to=n, by=1), 'y' = apply(rand_walk, 1, mean) ) # # Plot data # ggplot() + geom_line(data=all_walks, aes(x=Var1, y=value, group=Var2), color='#BCADDC', alpha=.5) + geom_line(data=avg_walk, aes(x=x, y=y), size = 1.3, color='#937EBF') + theme_fivethirtyeight() + theme(axis.title = element_text()) + xlab('Days') + ylab('Change in Stock Price (in $)') + ggtitle("Simulated Stock Prices")
 and moves one unit to the left with probability
and moves one unit to the left with probability 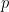 and moves one unit to the right with probability
and moves one unit to the right with probability 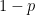 . What is the expected position
. What is the expected position ![\mathbb{E}[X_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002) of the particle after
of the particle after  steps?
steps?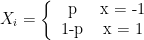

 . We can use rules of expected value to bring the expectation inside the summation and take the expectation of each individual
. We can use rules of expected value to bring the expectation inside the summation and take the expectation of each individual  as we normally would.
as we normally would.![\mathbb{E}[Y] = \mathbb{E}\big[\sum_{i=1}^{n} X_i \big]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%5Cmathbb%7BE%7D%5Cbig%5B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+X_i+%5Cbig%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[Y] = \sum_{i=1}^{n} \mathbb{E}[X_i]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Cmathbb%7BE%7D%5BX_i%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[Y] = \sum_{i=1}^{n} -1 \cdot p + 1 \cdot (1-p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D%C2%A0%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+-1+%5Ccdot+p+%2B+1+%5Ccdot+%281-p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[Y] = \sum_{i=1}^{n} 1 - 2p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%C2%A0%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+1+-+2p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[Y] = n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
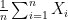 for
for  ,
,  . Suppose we want to do the same for the Cauchy distribution.
. Suppose we want to do the same for the Cauchy distribution.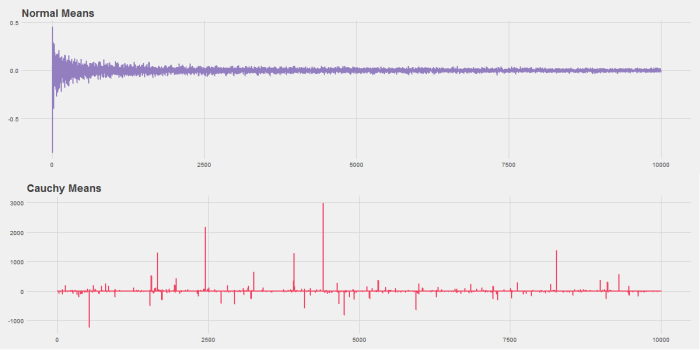

![n=0: \quad \mathbb{E}[X_0] = z_i](https://s0.wp.com/latex.php?latex=n%3D0%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_0%5D+%3D+z_i+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = (z_i - 1)p + (z_i + 1)(1 - p)](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+%28z_i+-+1%29p+%2B+%28z_i+%2B+1%29%281+-+p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = z_{i}p - p + z_i + 1 - z_{i}p - p](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+z_%7Bi%7Dp+-+p+%2B+z_i+%2B+1+-+z_%7Bi%7Dp+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = z_i + 1 - 2p](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+z_i+%2B+1+-+2p+&bg=ffffff&fg=000000&s=0&c=20201002)
 our position is now the result from
our position is now the result from  ,
,  .
.![n=2: \quad \mathbb{E}[X_2] = (z_i + 1 - 2p - 1)p + (z_i + 1 - 2p + 1)(1 - p)](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+%28z_i+%2B+1+-+2p+-+1%29p+%2B+%28z_i+%2B+1+-+2p+%2B+1%29%281+-+p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=2: \quad \mathbb{E}[X_2] = z_{i}p - 2p^2 + Z_i - 2p + 2 - z_{i}p + 2p^2 - 2p](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+z_%7Bi%7Dp+-+2p%5E2+%2B+Z_i+-+2p+%2B+2+-+z_%7Bi%7Dp+%2B+2p%5E2+-+2p&bg=ffffff&fg=000000&s=0&c=20201002)
![n=2: \quad \mathbb{E}[X_2] = z_i + 2(1 - 2p)](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+z_i+%2B+2%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_n] = z_i + n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+%3D+z_i+%2B+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002) . But we can prove this formally through induction. We’ve already done our base case, so let’s now do the induction step. We will assume that
. But we can prove this formally through induction. We’ve already done our base case, so let’s now do the induction step. We will assume that  .
.![\mathbb{E}[X_{n+1}] = (z_i + n(1 - 2p) - 1)p + (z_i + n(1 - 2p) + 1)(1 - p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+%28z_i+%2B+n%281+-+2p%29+-+1%29p+%2B+%28z_i+%2B+n%281+-+2p%29+%2B+1%29%281+-+p%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = (z_i + n - 2pn - 1)p + (z_i + n - 2pn + 1)(1 - p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+%28z_i+%2B+n+-+2pn+-+1%29p+%2B+%28z_i+%2B+n+-+2pn+%2B+1%29%281+-+p%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = z_{i}p + pn - 2p^{2}n - p + z_i + n - 2pn + 1 -z_{i}p - pn + 2p^{2}n - p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+z_%7Bi%7Dp+%2B+pn+-+2p%5E%7B2%7Dn+-+p+%2B+z_i+%2B+n+-+2pn+%2B+1+-z_%7Bi%7Dp+-+pn+%2B+2p%5E%7B2%7Dn+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = - p + z_i + n - 2pn + 1 - p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+-+p+%2B+z_i+%2B+n+-+2pn+%2B+1+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = z_i + (n + 1)(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+z_i+%2B+%28n+%2B+1%29%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_n] = n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+%3D+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002) .
. . This would mean we have an equal chance of moving left or moving right. Over the long run we would expect our final position to be exactly where we started. Plugging in
. This would mean we have an equal chance of moving left or moving right. Over the long run we would expect our final position to be exactly where we started. Plugging in 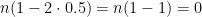 . Just as we expected! What if
. Just as we expected! What if  ? This means we only move to the left. Plugging
? This means we only move to the left. Plugging 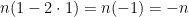 . This makes sense! If we can only move to the left then after
. This makes sense! If we can only move to the left then after  all distributed uniformly,
all distributed uniformly, 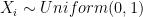 . We want to find the expected value of
. We want to find the expected value of ![\mathbb{E}[Y_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002) where
where  .
.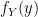 and we do so in the usual way, by first finding the Cumulative Distribution Function (CDF) and taking the derivative:
and we do so in the usual way, by first finding the Cumulative Distribution Function (CDF) and taking the derivative:
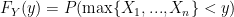
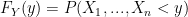


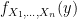 is a unit
is a unit 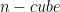 with area
with area  equal to
equal to 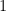 . In other words
. In other words  . Our equation then simplifies:
. Our equation then simplifies: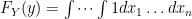
![F_Y(y) = \int dx_1 \dots \int dx_n = [F_X(y)]^n](https://s0.wp.com/latex.php?latex=F_Y%28y%29+%3D+%5Cint+dx_1+%5Cdots+%5Cint+dx_n+%3D+%5BF_X%28y%29%5D%5En+&bg=ffffff&fg=000000&s=0&c=20201002) where
where 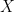 here is a generic random variable, by symmetry (all
here is a generic random variable, by symmetry (all  we can find
we can find ![f_Y(y) = \frac{d}{dy}F_Y(y) = \frac{d}{dy}[F_X(y)]^n](https://s0.wp.com/latex.php?latex=f_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7DF_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7D%5BF_X%28y%29%5D%5En+&bg=ffffff&fg=000000&s=0&c=20201002)
![f_Y(y) = n[F_X(y)]^{n-1}f_X(y)](https://s0.wp.com/latex.php?latex=f_Y%28y%29+%3D+n%5BF_X%28y%29%5D%5E%7Bn-1%7Df_X%28y%29+&bg=ffffff&fg=000000&s=0&c=20201002) by the chain rule.
by the chain rule. of a
of a  is
is  for
for ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . And by extension the CDF
. And by extension the CDF 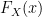 for a
for a 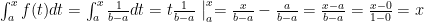 .
.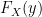 not
not 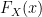 meaning we simply replace the
meaning we simply replace the  we just derived with
we just derived with 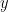 as we would in any normal function) we have:
as we would in any normal function) we have: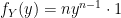
![\mathbb{E}[Y] = \int_{y\in A}yf_Y(y)dy = \int_0^1 yny^{n-1}dy = n\int_0^1 y^{n}dy = n\bigg[\frac{1}{n+1}y^{n+1}\bigg]_0^1 = \frac{n}{n+1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%5Cint_%7By%5Cin+A%7Dyf_Y%28y%29dy+%3D+%5Cint_0%5E1+yny%5E%7Bn-1%7Ddy+%3D+n%5Cint_0%5E1+y%5E%7Bn%7Ddy+%3D+n%5Cbigg%5B%5Cfrac%7B1%7D%7Bn%2B1%7Dy%5E%7Bn%2B1%7D%5Cbigg%5D_0%5E1+%3D+%5Cfrac%7Bn%7D%7Bn%2B1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
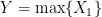 (which is simply
(which is simply  ;
; 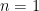 in this case) we get
in this case) we get  . This makes sense! If
. This makes sense! If 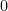 to
to  which is exactly what we got.
which is exactly what we got. . This also makes sense! If we take the maximum of 1 or 2 or 3
. This also makes sense! If we take the maximum of 1 or 2 or 3 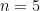 (thanks to the fantastic
(thanks to the fantastic