
After researching online basketball data in more depth I found that RealGM had so-called “split” data for college players. Players statistics are sliced in various ways such as performance against Top 25 teams.
n my original collection process involved scraping statistics from every college player, which was quite inefficient. It involved approximately 20,000 player-seasons worth of data and caused problems during the merge since so many players shared names. It also didn’t allow collection of the “split” data since these is housed on each player’s individual page instead of on the “All College Player Stats” page.
It was quite challenging figuring out how to scrape the RealGM site. The page structure was predictable aside from a unique id number for every player, which I assume comes from some sort of internal database on the RealGM site. These numbers range in length from two to five numerals and there is no way I could find to predict these numbers. For instance, Carmelo Anthony’s player page link is below. His player id is 452.
http://basketball.realgm.com/player/Carmelo-Anthony/NCAA/452/2014/By_Split/
Advanced_Stats/Quality_Of_Opp
After a fair bit of thrashing about I finally came up with the solution to write an R script that would google the first portion of the player’s page link, read the Google page source, search for player’s site address using regular expressions, and then append their id to the rest of the structured web address.
For Carmelo, the script would use the following google search link:
https://www.google.com/search?q=realgm.com/player/Carmelo-Anthony
The specificity of the search ensures that the RealGM link appears on the first page of search results (it was the first result in every test scenario I tried). The script then uses the following regular expression when search the Google search results page source:
realgm.com/player/Carmelo-Anthony/(Summary|News|\u2026)/[0-9]+
A player’s main page is always preceded by the player’s name and then “/Summary/id”, but “/News/id” and “/…/id” also appeared. After it locates and reads this link it’s easy enough to strip out the player id and insert it into the player’s page that links to the advanced college data I was looking for.
library(XML) library(RCurl) library(data.table) # Read in players and convert names to proper format players.DF <- read.csv(file="~/.../Combined Data/Combined Data 1.csv") players <- as.character(players.DF$Player) players <- gsub("\\.","",players) players <- gsub(" ","-",players) # Initialize dataframes and vectors missedPlayers <- NULL playerLinks <- rep(NA, length(players)) playerLinks <- data.frame(players.DF$Player, playerLinks) # Create link for each player for(i in 1:length(players)) { url <- paste0('https://www.google.com/search?q=realgm.com/player/',players[i]) result <- try(content <- getURLContent(url)) if(class(result) == "try-error") { next; } id <- regexpr(paste0("realgm.com/player/", players[i], "/(Summary|News|\u2026)","/[0-9]+"),content) id <- substr(content, id, id + attr(id,"match.length")) id <- gsub("[^0-9]+","",id) id <- paste0('http://basketball.realgm.com/player/', players[i], '/NCAA/', id,'/2014/By_Split/Advanced_Stats/Quality_Of_Opp') playerLinks[i,2] <- id } setnames(playerLinks, c("players.DF.Player","playerLinks"), c("Players","Links"))
Some sites have started to detect and try to prevent web scraping. On iteration 967 Google began blocking my search requests. However, I simply reran the script the next morning from iteration 967 onward to pickup the missing players.
I then used the fact that a missing id results in a page link with “NCAA//” to search for players that were still missing their ids.
After examining the players I noticed many of these had apostrophes in their name, which I had forgotten to account for in my original name formatting.
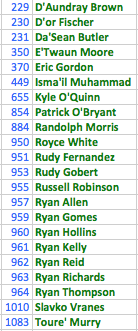
I adjusted my procedure and reran the script to get the pickups.
pickups <- playerLinks[which(grepl("NCAA//",playerLinks[[2]])),] pickups <- pickups[[1]] pickups <- gsub("'","",pickups) pickups <- gsub(" ","-",pickups) pickupNums <- grep("NCAA//",playerLinks[[2]]) for(i in 1:length(pickupNums)) { j <- pickupNums[i] url <- paste0('https://www.google.ca/search?q=realgm.com/player/',pickups[i]) result <- try(content <- getURLContent(url)) if(class(result) == "try-error") { next; } id <- regexpr(paste0("realgm.com/player/", pickups[i], "/(Summary|News|\u2026)","/[0-9]+"),content) id <- substr(content, id, id + attr(id,"match.length")) id <- gsub("[^0-9]+","",id) id <- paste0('http://basketball.realgm.com/player/', pickups[i], '/NCAA/', id,'/2014/By_Split/Advanced_Stats/Quality_Of_Opp') playerLinks[[j,2]] <- id }
After rerunning the script three players were still missing ids, so I entered these manually.
playerLinks[[370,2]] <- "http://basketball.realgm.com/player/Eric-Gordon/NCAA/762/2014/By_Split/Advanced_Stats/Quality_Of_Opp" playerLinks[[884,2]] <- " http://basketball.realgm.com/player/Randolph-Morris/NCAA/166/2014/By_Split/Advanced_Stats/Quality_Of_Opp" playerLinks[[1010,2]] <- "http://basketball.realgm.com/player/Slavko-Vranes/NCAA/472/2014/By_Split/Advanced_Stats/Quality_Of_Opp"
I also needed to manually check the three duplicate players and adjust their ids accordingly.
The final result looks like this:
The next step will be to cycle through the links and use readHTMLTable() to get the advanced statistics.
