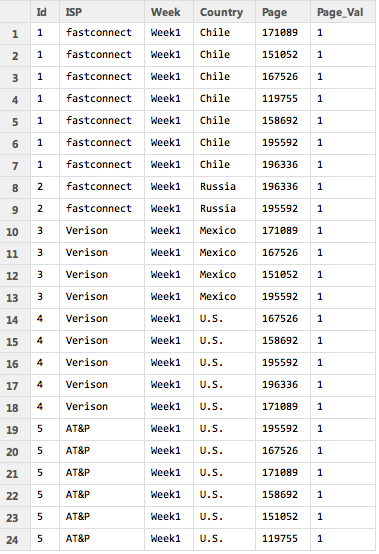
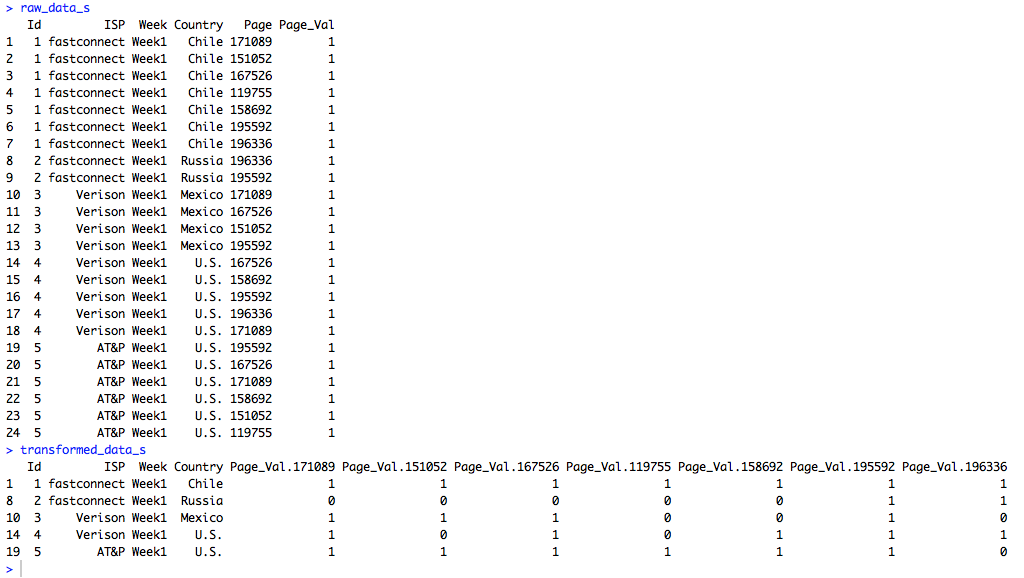
Driving for Lyft before I start a new job. Here are a few thoughts:
3 ways Google Maps fails
- When there is short-term construction that closes a road.
- When roads are layered on top of one another, for example a viaduct running atop a ground-level artery.
- When it needs to know where the front door is. Is the front door on the street side or the alley side of a skyscraper? Google doesn’t seem to know. Just today it wanted me to take the freeway onramp and then stop so I could let a passenger out at the Seattle Facebook office.
Computer chess, presentation of self, and the best way to get to work
Everyone has a preferred way to get to work in the morning. They sometimes have preferred ways to get to bars and the such, but there is something special about getting to work in the best, most creative way possible. There is usually a “secret” route or “shortcut.” This is sometimes presented passive-aggressively as we in Seattle are famous for being: “Now, when I drive I turn right here and then make an illegal u-turn. But I don’t have my drivers do that.” Sooooo…I should make the illegal u-turn right?
I was talking to a passenger and told him about the preferred route everyone had to work and how I would sometimes overhear them telling their friend about how much faster their way was than a coworkers’. He said, “It’s like they take pride in it.” Exactly. More and more I think most of our behavior is signaling. I’m currently reading The Presentation of Self in Everyday Life. Performances are very much on display even in the short trip to work in the back of a stranger’s car.
Their “special” directions often override Google Maps (I keep the speaker on so they can hear the directions it’s telling me). They say, “I don’t know why it’s telling you to go that way, you should turn left here.” I do and it’s always slower. It reminds me of Tyler Cowen’s thoughts on computer-human chess. A computer-human combination can beat a computer alone, but the trick is to almost always defer to the computer. Likewise, Google Maps isn’t perfect, but 9 times out of 10 I’d say it’s faster than your secret “shortcut.” For one thing it knows about dynamic traffic conditions. It’s also, you know, a computer so it’s designed to make calculations about getting you from point A to B that aren’t biased by your competition with your coworker about who has the best route to work. I mean, just think about how much data Google Maps must have. Every time you use it you’re loading it with more information about how long it took you to get from Cherry Street to Spring Street on a certain day at a certain time in certain weather conditions. It basically has infinite data on driving routes in every major U.S. city.
Seeing the city through others’ eyes
“You have to turn right. You see if you go straight the road turns into 2nd Avenue Extension, but if you want to just stay on 2nd Avenue you have to turn right.” He said this with an air of disbelief, trying not to laugh. He told me the streets in Vancouver, Canada make more sense. It helps to know about the history of Seattle. It struck me that street creation in Seattle was a bit Hayek, planned in the short term, but emergent over the long term.
A young man visiting from Salt Lake said the air was too polluted. He loves the rain in Seattle.
I drove two men to the Woodland Park Zoo. They had come for a work trip and stayed an extra weekend. They told me they had made it a habit of visiting zoos wherever they traveled.
Surprises
I did not anticipate how much my butt would hurt. Like really hurt. But I guess I’m surprised that I’m surprised since I should have anticipated that sitting down all day would hurt my butt. Also surprising how fast a cell phone battery runs out when constantly using Lyft and Google Maps apps. And I’m surprised by how much time I spend alone. It seems like well over half the day is spent driving around looking for passengers. When I finally find someone it’s like “Thank God!” I don’t have to be alone anymore.
People are good
I’ll never understand Misanthropes. I’ve used online dating sites to go on 50+ first dates and have now given 150 Lyft rides. A small sample in the grand scheme of things, but I suspect a much richer sample than those that fear the downfall of society. Maybe the only things I’ve learned for sure is that people are good. Or even more fundamentally, people are just trying to carve out a living in this crazy world. Some are happy to sit quietly or check email, but many want to engage and learn. Interacting so often makes me feel apart of the world more richly and deeply than I had anticipated (perhaps this should have gone under surprises).
Actually, about 15+% of the time I want to keep hanging out with the person I’m driving and get a little sad I have to drop them off. I want to be like, “Hey…can I come eat dinner with you guys?”
Surge pricing
If supply doesn’t match demand surge pricing is invoked for the passenger. I’ve seen it go up to 200% of a normal fare. This is indicated in the Lyft driver app by a heat map overlaid on the portions of the city where surge pricing is currently in effect. It seems to work much more on the demand side than the supply side. That is, passengers just don’t want to pay the fare so they don’t request a car. In economic theory it’s also meant to send a signal to producers – in this case cars – to “produce” more (drive to that area). However, often the surge pricing is only in effect for a few minutes, or even a few seconds. It reminds me of that line from Pirates of the Caribbean about Isla de Muerta, which can only be found by those that already know where it is. You can only take advantage of surge pricing if you’re already in the area where surge pricing is in effect. Don’t try to drive to it because you won’t make it. As Wayne Gretzky said, “Skate to where the puck is going, not to where it is.” About 150 rides in and I have yet to pick up a passenger that was paying a surge pricing fare.
Perks
Driving allows a flexible schedule so I can take a few hours on a sunny afternoon off if I want to read about sociology in the park, study Real Analysis or Computational Finance, or watch the latest season of the Americans.
Pay
Everyone wants to know about pay. The pay isn’t that great so I’m finding I don’t really have time to do any of those things I just mentioned. The key is to try to keep people in your car. That’s when you can consistently make $20-$25 per hour. But that’s easier said than done.


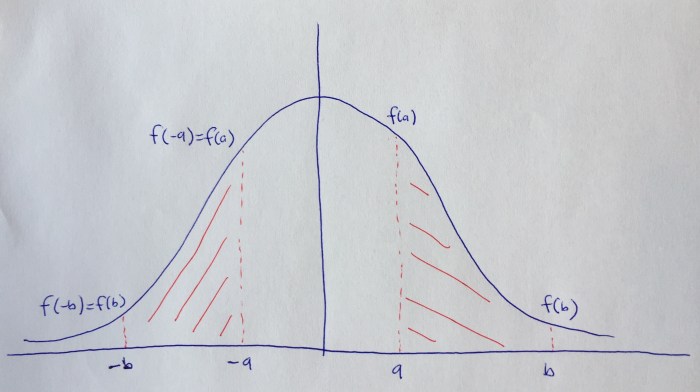

 and
and  :
:

 :
:
 is even so
is even so  :
:

![= \lim_{t \to \infty} [F(t)] - F(x)](https://s0.wp.com/latex.php?latex=%3D+%5Clim_%7Bt+%5Cto+%5Cinfty%7D+%5BF%28t%29%5D+-+F%28x%29+&bg=ffffff&fg=000000&s=0&c=20201002)