
MIT has a cute little problem in their calculus problem set, which you can see here. I like this problem because it takes something complicated and shows that it actually reduces down to something very simple.
To start this problem off let’s suppose we have a function that we can write as the product of two other functions, 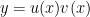
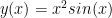
To find the derivative we would need to use the power rule. To get warmed up let’s take two derivatives of

Applying the rule again we get four terms, two from the first product and two from the second:

We can combine terms to get:
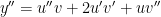
This process can continue and indeed the problem set gives us Libniz’s formula for the n-th derivative, which is:

This formula may look daunting at first, but it’s really pretty simple. Note that we are not raising our functions to powers, 
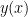
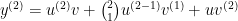

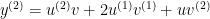
This is exactly what we got above, the only difference is the notation.
The problem now asks us to calculate 
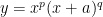
Before we begin let’s make a few observations that will help us along the way. First, in this example our 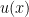


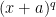
Next, let me remind you about two well known facts of 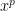
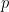
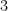
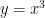


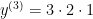

So what have we learned? Well, first we know that all derivatives higher than order
The second thing to notice is that the p-th derivative is actually 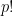



These two rules also hold for 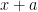
Given what we’ve learned let’s move forward writing out the first few terms of Leibniz’s formula with our given
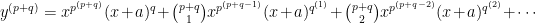
So far all of these terms are 0 since the derivatives of 
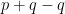
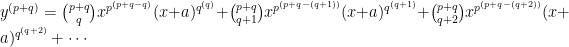
Notice what happens here. For derivatives of order higher than 

But this can be simplified using our rules from above. We can replace 
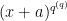
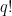

And now we can expand the binomial term. Recall that 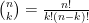
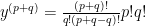


See what I mean! The derivatives of the product of two fairly general functions just turns into a few multiplications.
 and moves one unit to the left with probability
and moves one unit to the left with probability 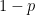 . What is the expected position
. What is the expected position ![\mathbb{E}[X_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002) of the particle after
of the particle after  steps?
steps?
![n=0: \quad \mathbb{E}[X_0] = z_i](https://s0.wp.com/latex.php?latex=n%3D0%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_0%5D+%3D+z_i+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = (z_i - 1)p + (z_i + 1)(1 - p)](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+%28z_i+-+1%29p+%2B+%28z_i+%2B+1%29%281+-+p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = z_{i}p - p + z_i + 1 - z_{i}p - p](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+z_%7Bi%7Dp+-+p+%2B+z_i+%2B+1+-+z_%7Bi%7Dp+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=1: \quad \mathbb{E}[X_1] = z_i + 1 - 2p](https://s0.wp.com/latex.php?latex=n%3D1%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_1%5D+%3D+z_i+%2B+1+-+2p+&bg=ffffff&fg=000000&s=0&c=20201002)
 our position is now the result from
our position is now the result from  ,
,  .
.![n=2: \quad \mathbb{E}[X_2] = (z_i + 1 - 2p - 1)p + (z_i + 1 - 2p + 1)(1 - p)](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+%28z_i+%2B+1+-+2p+-+1%29p+%2B+%28z_i+%2B+1+-+2p+%2B+1%29%281+-+p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![n=2: \quad \mathbb{E}[X_2] = z_{i}p - 2p^2 + Z_i - 2p + 2 - z_{i}p + 2p^2 - 2p](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+z_%7Bi%7Dp+-+2p%5E2+%2B+Z_i+-+2p+%2B+2+-+z_%7Bi%7Dp+%2B+2p%5E2+-+2p&bg=ffffff&fg=000000&s=0&c=20201002)
![n=2: \quad \mathbb{E}[X_2] = z_i + 2(1 - 2p)](https://s0.wp.com/latex.php?latex=n%3D2%3A+%5Cquad+%5Cmathbb%7BE%7D%5BX_2%5D+%3D+z_i+%2B+2%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_n] = z_i + n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+%3D+z_i+%2B+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002) . But we can prove this formally through induction. We’ve already done our base case, so let’s now do the induction step. We will assume that
. But we can prove this formally through induction. We’ve already done our base case, so let’s now do the induction step. We will assume that  .
.![\mathbb{E}[X_{n+1}] = (z_i + n(1 - 2p) - 1)p + (z_i + n(1 - 2p) + 1)(1 - p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+%28z_i+%2B+n%281+-+2p%29+-+1%29p+%2B+%28z_i+%2B+n%281+-+2p%29+%2B+1%29%281+-+p%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = (z_i + n - 2pn - 1)p + (z_i + n - 2pn + 1)(1 - p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+%28z_i+%2B+n+-+2pn+-+1%29p+%2B+%28z_i+%2B+n+-+2pn+%2B+1%29%281+-+p%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = z_{i}p + pn - 2p^{2}n - p + z_i + n - 2pn + 1 -z_{i}p - pn + 2p^{2}n - p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+z_%7Bi%7Dp+%2B+pn+-+2p%5E%7B2%7Dn+-+p+%2B+z_i+%2B+n+-+2pn+%2B+1+-z_%7Bi%7Dp+-+pn+%2B+2p%5E%7B2%7Dn+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = - p + z_i + n - 2pn + 1 - p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+-+p+%2B+z_i+%2B+n+-+2pn+%2B+1+-+p+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_{n+1}] = z_i + (n + 1)(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7Bn%2B1%7D%5D+%3D+z_i+%2B+%28n+%2B+1%29%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X_n] = n(1 - 2p)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_n%5D+%3D+n%281+-+2p%29+&bg=ffffff&fg=000000&s=0&c=20201002) .
. . This would mean we have an equal chance of moving left or moving right. Over the long run we would expect our final position to be exactly where we started. Plugging in
. This would mean we have an equal chance of moving left or moving right. Over the long run we would expect our final position to be exactly where we started. Plugging in 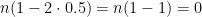 . Just as we expected! What if
. Just as we expected! What if  ? This means we only move to the left. Plugging
? This means we only move to the left. Plugging 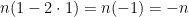 . This makes sense! If we can only move to the left then after
. This makes sense! If we can only move to the left then after 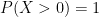 and are given that
and are given that ![\lim_{n\to\infty} x\big[1-F(x)\big] = 0](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn%5Cto%5Cinfty%7D+x%5Cbig%5B1-F%28x%29%5Cbig%5D+%3D+0+&bg=ffffff&fg=000000&s=0&c=20201002) . Show that
. Show that ![\mathbb{E}[X] = \int_0^{\infty} P(X > x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002) .
.![\mathbb{E}[X] = \int_{-\infty}^{\infty}xf_X(x)dx = \int_0^{\infty}xf_X(x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7Dxf_X%28x%29dx+%3D+%5Cint_0%5E%7B%5Cinfty%7Dxf_X%28x%29dx&bg=ffffff&fg=000000&s=0&c=20201002) since we are given
since we are given 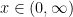 .
.
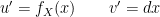
 and plugging in our selections we get:
and plugging in our selections we get:![\mathbb{E}[X] = \int_0^{\infty}xf_X(x)dx = xF_X(x)\bigm|_0^{\infty} - \int_0^{\infty} F_X(x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint_0%5E%7B%5Cinfty%7Dxf_X%28x%29dx+%3D+xF_X%28x%29%5Cbigm%7C_0%5E%7B%5Cinfty%7D+-+%5Cint_0%5E%7B%5Cinfty%7D+F_X%28x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002)
 as
as 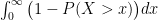 . This simplifies to
. This simplifies to 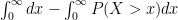 . Let’s plug this back into our equation above:
. Let’s plug this back into our equation above:![\mathbb{E}[X] = \int_0^{\infty}xf_X(x)dx = xF_X(x)\bigm|_0^{\infty} - \bigg(\int_0^{\infty} dx - \int_0^{\infty} P(X > x)dx \bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint_0%5E%7B%5Cinfty%7Dxf_X%28x%29dx+%3D+xF_X%28x%29%5Cbigm%7C_0%5E%7B%5Cinfty%7D+-+%5Cbigg%28%5Cint_0%5E%7B%5Cinfty%7D+dx+-+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+%5Cbigg%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X] = xF_X(x)\bigm|_0^{\infty} - x\bigm|_0^{\infty} + \int_0^{\infty} P(X > x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+xF_X%28x%29%5Cbigm%7C_0%5E%7B%5Cinfty%7D+-+x%5Cbigm%7C_0%5E%7B%5Cinfty%7D+%2B+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X] = \big[xF_X(x)- x\big]_0^{\infty} + \int_0^{\infty} P(X > x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cbig%5BxF_X%28x%29-+x%5Cbig%5D_0%5E%7B%5Cinfty%7D+%2B+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X] = \big[x(F_X(x)- 1)\big]_0^{\infty} + \int_0^{\infty} P(X > x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cbig%5Bx%28F_X%28x%29-+1%29%5Cbig%5D_0%5E%7B%5Cinfty%7D+%2B+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[X] = \big[-x(1-F_X(x))\big]^{x=\infty} + \int_0^{\infty} P(X > x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cbig%5B-x%281-F_X%28x%29%29%5Cbig%5D%5E%7Bx%3D%5Cinfty%7D+%2B+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002) since plugging in
since plugging in 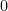 to the first half of our expression just yields
to the first half of our expression just yields  at infinity, instead we take the limit:
at infinity, instead we take the limit:![\mathbb{E}[X] = -\lim_{x\to\infty} x\big[1-F(x)\big] + \int_0^{\infty} P(X > x)dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%3D+-%5Clim_%7Bx%5Cto%5Cinfty%7D+x%5Cbig%5B1-F%28x%29%5Cbig%5D+%2B+%5Cint_0%5E%7B%5Cinfty%7D+P%28X+%3E+x%29dx+&bg=ffffff&fg=000000&s=0&c=20201002) , but recall that we are told
, but recall that we are told ![\lim_{x\to\infty} x\big[1-F(x)\big] = 0](https://s0.wp.com/latex.php?latex=%5Clim_%7Bx%5Cto%5Cinfty%7D+x%5Cbig%5B1-F%28x%29%5Cbig%5D+%3D+0+&bg=ffffff&fg=000000&s=0&c=20201002) and so we are simply left with:
and so we are simply left with: all distributed uniformly,
all distributed uniformly, 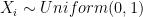 . We want to find the expected value of
. We want to find the expected value of ![\mathbb{E}[Y_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002) where
where  .
.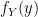 and we do so in the usual way, by first finding the Cumulative Distribution Function (CDF) and taking the derivative:
and we do so in the usual way, by first finding the Cumulative Distribution Function (CDF) and taking the derivative:
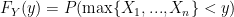
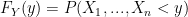

 ‘s are in fact independent. Thanks to Ryan for helping me see that by definition:
‘s are in fact independent. Thanks to Ryan for helping me see that by definition:
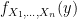 is a unit
is a unit 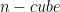 with area
with area  equal to
equal to 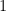 . In other words
. In other words  . Our equation then simplifies:
. Our equation then simplifies: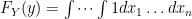
![F_Y(y) = \int dx_1 \dots \int dx_n = [F_X(y)]^n](https://s0.wp.com/latex.php?latex=F_Y%28y%29+%3D+%5Cint+dx_1+%5Cdots+%5Cint+dx_n+%3D+%5BF_X%28y%29%5D%5En+&bg=ffffff&fg=000000&s=0&c=20201002) where
where 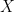 here is a generic random variable, by symmetry (all
here is a generic random variable, by symmetry (all  we can find
we can find ![f_Y(y) = \frac{d}{dy}F_Y(y) = \frac{d}{dy}[F_X(y)]^n](https://s0.wp.com/latex.php?latex=f_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7DF_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7D%5BF_X%28y%29%5D%5En+&bg=ffffff&fg=000000&s=0&c=20201002)
![f_Y(y) = n[F_X(y)]^{n-1}f_X(y)](https://s0.wp.com/latex.php?latex=f_Y%28y%29+%3D+n%5BF_X%28y%29%5D%5E%7Bn-1%7Df_X%28y%29+&bg=ffffff&fg=000000&s=0&c=20201002) by the chain rule.
by the chain rule. of a
of a  is
is  for
for ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . And by extension the CDF
. And by extension the CDF 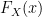 for a
for a 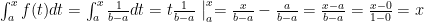 .
.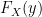 not
not 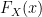 meaning we simply replace the
meaning we simply replace the 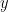 as we would in any normal function) we have:
as we would in any normal function) we have: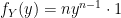
![\mathbb{E}[Y] = \int_{y\in A}yf_Y(y)dy = \int_0^1 yny^{n-1}dy = n\int_0^1 y^{n}dy = n\bigg[\frac{1}{n+1}y^{n+1}\bigg]_0^1 = \frac{n}{n+1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D+%3D+%5Cint_%7By%5Cin+A%7Dyf_Y%28y%29dy+%3D+%5Cint_0%5E1+yny%5E%7Bn-1%7Ddy+%3D+n%5Cint_0%5E1+y%5E%7Bn%7Ddy+%3D+n%5Cbigg%5B%5Cfrac%7B1%7D%7Bn%2B1%7Dy%5E%7Bn%2B1%7D%5Cbigg%5D_0%5E1+%3D+%5Cfrac%7Bn%7D%7Bn%2B1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
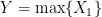 (which is simply
(which is simply  ;
; 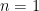 in this case) we get
in this case) we get  . This makes sense! If
. This makes sense! If  is just a uniform random variable on the interval
is just a uniform random variable on the interval  which is exactly what we got.
which is exactly what we got. . This also makes sense! If we take the maximum of 1 or 2 or 3
. This also makes sense! If we take the maximum of 1 or 2 or 3 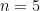 (thanks to the fantastic
(thanks to the fantastic 