
For fun I’m enrolled in an online computational finance certificate at UW. In one of my homework problems I wanted to use the following fact about the integral of single variable, even functions:

If it’s been a few years since you’ve taken calculus that may not make much sense, but trust me when I tell you that it’s analytically obvious, especially when looking at functions graphically, as this terrible hand drawn image shows:
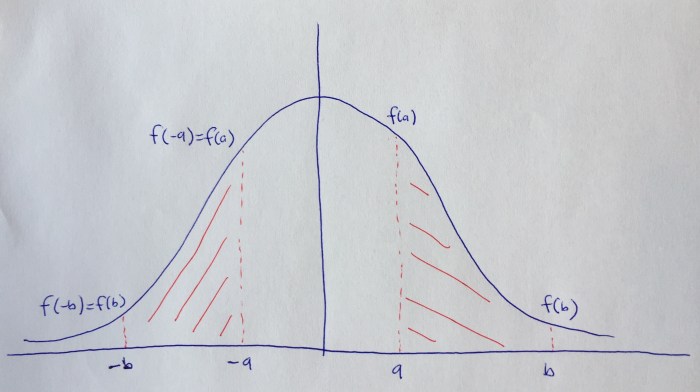
Intuitively, we know the two red areas are the same, so it seems we should be able to interchange the limits as I described above. Indeed, playing around in Mathematica suggests that this is true. However, I could not find a proof or theorem for this online so perhaps it is rarely used. I decided to prove it myself:
Original equation:

Use u-substitution with 


Bring minus sign outside integral:

Use the fact that 

By assumption 


Rewrite improper integral:

By Fundamental Theorem of Calculus:
![= \lim_{t \to \infty} [F(t)] - F(x)](https://s0.wp.com/latex.php?latex=%3D+%5Clim_%7Bt+%5Cto+%5Cinfty%7D+%5BF%28t%29%5D+-+F%28x%29+&bg=ffffff&fg=000000&s=0&c=20201002)
By Fundamental Theorem of Calculus:

Which is exactly the result we were trying to obtain.

